1. MapReduce工作机制
MapReduce执行总流程
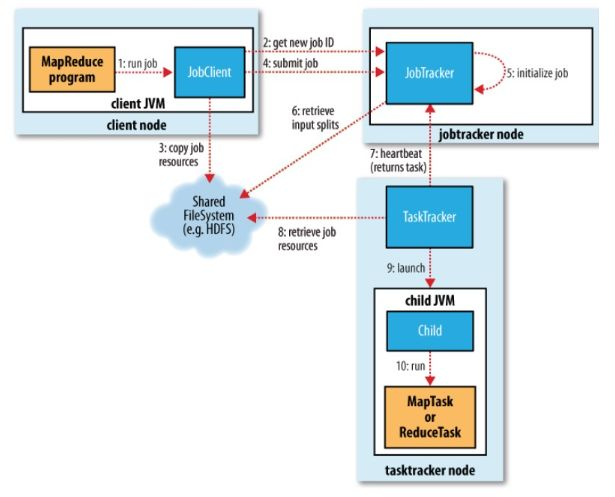
MapReduce Framework如上图所示。
JobTracker: 初始化作业,分配作业,与TaskManager通信,协调整个作业的执行
TaskTracker: 保持与JobTracker的通信,执行map或者reduce任务
HDFS;保存作业的数据,配置信息等,保存作业结果
具体相关流程
提交作业
客户端编写完程序代码后,打成jar,然后通过相关命令向集群提交自己想要跑的MR任务,具体过程如下:
- 通过调用JobTracker的getNewJobId()获取当前作业id
- 检查作业相关路径
- 计算作业的输入划分,并将划分信息写到Job.split文件中
- 将运行作业所需要的资源包括作业jar包,配置文件和打算所得的输入划分,复制到作业对应的HDFS上
- 调用JobTracker的summitJob()提交,告诉JobTracker作业准备执行
初始化作业
- 从HDFS中读取作业对应的job.split,得到输入数据的划分信息
- 创建并且初始化Map任务和Reduce任务:为每个map/reduce task生成一个TaskInProgress去监控和调度该task。例如创建两个初始化task,一个初始化Map,一个初始化Reduce
分配任务
JobTracker会将任务分配到TaskTracker去执行,但是怎么判断哪些TaskTracker,怎么分配任务呢?所以,我们要实现JobTracker和TaskTracker中的通信,也就是TaskTracker循环向JobTracker发送心跳,向上级报告自己这边是不是还活着,活干的怎么样了,可以接些新活等。作为JobTracker,接收到心跳信息,如果有待分配任务,就会给这个TaskTracker分配一个任务,然后taskTracker就把这个任务加入到他的任务队列中。我们可以主要看看TaskTracker中的transmitHeartBeart()和JobTracker的heartbeat()方法。
执行任务
TaskTracker申请到任务后,在本地执行,主要有以下几个步骤来完成本地的步骤化:
- 将job.split复制到本地
- 将job.jar复制到本地
- 将job的配置信息写入到Job.xml
- 创建本地任务目录,解压job.rar
- 调用launchTaskForJob()方法发布任务
发布任务后,TaskRunner会启动新的java虚拟机来运行每个任务,以map任务为例,流程如下:
- 配置任务执行参数(获取java程序的执行环境和配置参数等)
- 在child临时文件表中添加Map任务信息
- 配置log文件夹,配置Map任务的执行环境和配置参数;
- 根据input split,生成RecordReader读取数据
- 为Map任务生成MapRunnable,一次从RecordReader中接收数据,并调用map函数进行处理
- 将Map函数的输出调用collect收集到MapOUtputBuffer中
2. MapReduce中排序应用
实现过程
Map阶段
Read(读取) ==> Collect(生成Key-Value) ==> Spill(溢写)
Read:从HDFS读取inputSplit(由InputFormat根据文件生成)
Collect:分为map过程和partition过程,map根据inputSplit生成Key-Value对,而Partition添加分区标记(辅助排序用),并写入环形缓存区。
Spill:分为sort过程、compress过程以及combine过程。数据不断的写入环形缓存区,达到阈值之后开始溢写,在溢写的过程中进行一次Sort,这里使用的排序是快排(QuickSort);一次溢出生成一个file,并且在生成file的过程中进行压缩(compress);多个file又会进行一次文件合并,在文件合并的过程中进行排序,这里使用的排序是归并排序(MergeSort)。
Shuffle阶段
Shuffle阶段主要就是一个数据拷贝的过程,Map端合成的大文件之后,通过HTTP服务(jetty server)拷贝到Reduce端。拷贝到Reduce端的数据并不是马上写入文件,而是同样放在缓存中,达到阈值则进行溢写。
Reduce阶段
合并溢写生成的file,这里使用的排序为归并排序(MegerSort),生成一些更大的文件(进一步减少文件个数)。在归并之后留下少量的大文件,最后对大文件进行一次最终合并,合并成一个有序的大文件(只有一个),这里使用的排序算法为堆排序(HeapSort)。
总结
综上所述,一个MapReduce过程涉及到了一次快排、两次归并以及一次堆排的操作。

