论文摘要
现阶段关系抽取方法采用多示例学习与提供的语义与语境信息有效的确定关系类别。这样模型会识别偏向于高精确率的关系,忽略那些关系长尾句子中(in the long tail),为了解决这个问题,利用预训练语言模型Open AI Generative Pre-trained Transformer(GPT),除了从词法句法的角度解决问题外,也更注重大量的常识知识(一些重要的特征识别更多元的关系),在高召回率情况下在NYT10数据集下实现较好的效果。
简介
关系抽取是许多自然语言处理应用的关键组件,例如知识库普及与问答系统。远程监督是一种流行方法启发式生成标签数据用于训练关系抽取系统,方法是通过对齐文本中的实体元组与已知关系示例来自于知识库中,但是存在噪声标签与知识库信息不完全。
现阶段关系抽取方法解决问题是通过多示例学习与显式提供语义和句法知识指导模型,例如:词性与文法依赖信息。最近的方法利用附加信息,例如:意译、关系别名与实体类型。但是依旧会出现摘要中提到的问题。
深度语言表示,例如那些由Transformer通过语言建模学到的,已经被证实通过无监督的预训练就可以隐式地捕获文本的有价值的语义与句法属性,并在广泛的自然语言处理任务中取得不错的效果。文章假设预训练语言模型为远程监督提供一个强烈的信号,更好的基于知识获取指导关系抽取任务。使用隐形特征代替显性语言知识与附加信息提高领域和语言的独立性,并且能够增加识别出关系的多样性。
在文章中,引入一个远程监督关系抽取Transformer模型。文章扩展标准的Transformer模型通过一个有选择性的注意力机制处理多示例学习与预测,整个过程直接微调模型在远程监督关系抽取。文章提及该处理最小化显式特征提取并降低错误累积的风险。此外,文章引入自注意结构允许模型有效地长期依赖关系。
论文贡献:
将GPT应用于远程监督数据集包级、多示例训练与预测,对句子级信息采用注意力机制进行选择聚合产生包级预测。
在NTY数据集上实现较好的(Area of Under Curve)AUC效果,相比于RESIDE,PCNN+ATT in held-out evaluation.
手动评估跟踪结果,证明模型预测了一组更加多样化的关系,并在高召回率下表现良好。
- 开源贡献:https://github.com/DFKI-NLP/DISTRE
模型方法
Transformer-Decoder模型
Transformer-Decoder在多个层上重复编码给定的输入表示(Transformer 块),包含掩码多头注意力机制接一个position-wise feedforward operation.,不同于原始的Transformer,鉴于没有编码器,模型不同于原始模型,不含任何形式的无掩码自注意力机制。
$T$ 是一个句子中词索引的one-hot 行向量矩阵 ,$W_e$是词向量矩阵,$W_p$是位置向量矩阵,$L$是Transformer块数,$h_t$表示$l$层的state。之所以加入词位置向量在于Transformer模型本身不含隐性的位置信息,自注意结构有效的解决长距离依赖。
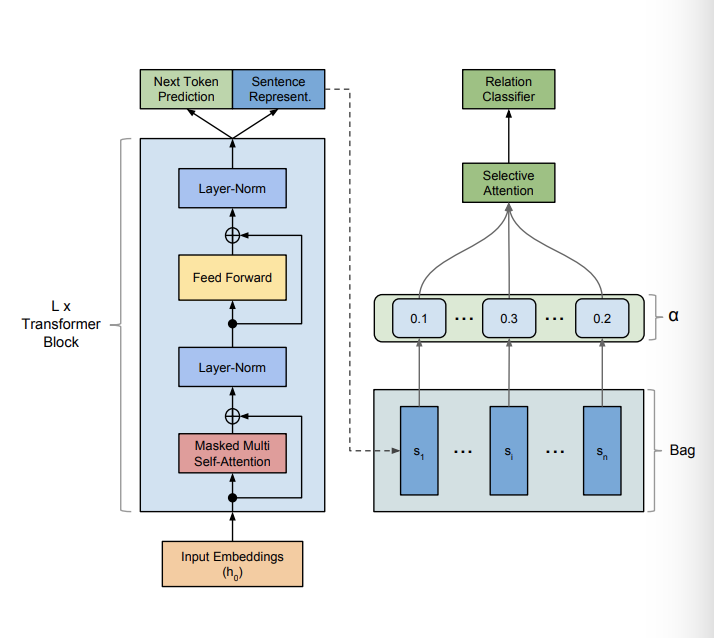
contextualized representations语言模型学习方法
无监督预训练语言表示模型采用最大似然估计作为损失函数,其中$k$表示上下文窗口数,通过条件概率$P$预测下一个词$c_i$ (貌似只是单向的),Transformer模型目标函数:
整个优化过程采用随机梯度下降,该结果是对于每一个词的概率分布用于下游任务的输入序列。
Transformer多示例学习
实现包级别多示例学习在Transformer结构基础上,文章假设一个标记的数据可以表示为$D =\lbrace(xi,head_i,tail_i,r_i)\rbrace{i=1}^N$,其中$head_i$与$tail_i$是相对于头尾实体的相对位置,$x_i$是每个例子包含的输入词序列(句子表示)$x_i = [x^1,…x^m]$。对于包中句子$S=\lbrace x_1,x_2,…,x_n\rbrace$每一个词序列(句子)通过预训练模型使用最后一个状态表示$h_L$的最后一个状态$h_L^m$对应于$x_i$的每一个表示$s_i$,使用$s$用于分类,公式如下:
选择注意力可以学习认清那些带有明显特征表示某个关系的句子同时不重视那些包含噪音的句子,权重计算公式如下:
最终优化目标如下:
由于引入语言模型在微调过程中有助于改善泛化能力实现快速收敛,故:
标量$\lambda$反映微调期间语言模型的权重值。
模型输入的特殊性-BPE编码算法
充分利用分词信息,使用byte pair encoding(BPE)对输入文本分词。BPE是用来解决未登录词问题的一种方法。在做NLP的时候,我们通常会对语料做一个预处理,生成语料的一个字典。为了不让字典太大,我们通常只会把出现频次大于某个阈值的词丢到字典里边,剩下所有的词都统一编码成#UNK。这是很经典很朴素的做法,这种方法不能解决未登录词的问题。未登录词是指在验证集或测试集出现了但训练集从来没见到过的单词。这种未登录词对分词、NLP其他任务性能有很大影响。常见的解决方法有:给低频词设置一个back-off表,当出现低频词的时候就去查表;或者不做word-level的东西,转做char-level的东西,因为不管什么词肯定是由若干个字母组成的。
两种方法各有优劣。第一种方法,简单直接,若干back-off做的很好会对低频词处理有很大提升(机器翻译);但这种方法依赖于back-off表的质量,而且也没法处理非登录词问题。第二种方法,从源头解决未登录词的问题,但是模型粒度太细,一般出来的效果不是特别好。我认为可能非串级别导致词信息损失过多。
2016年《Neural Machine Translation of Rare Words with Subword Units》提出了基于subword来生成词典的方法。他的核心思想是综合word-level and char-level的优势,从语料中学习到所有词里边频次高的字符串子串。然后把这些频次高的字符串子串收集起来形成一个字典。这个字典里边,既存在char-level级别字符也存在word-level级别的子串。然后把这个字典用于模型的训练。论文在寻找频次高的子串时,使用了BPE算法,就是把子串encoding:每次合并在语料中同一个词里面的、相邻的、出现频率最高的两个子串。decoding的时候,根据生成的voc.txt做相应的替换。
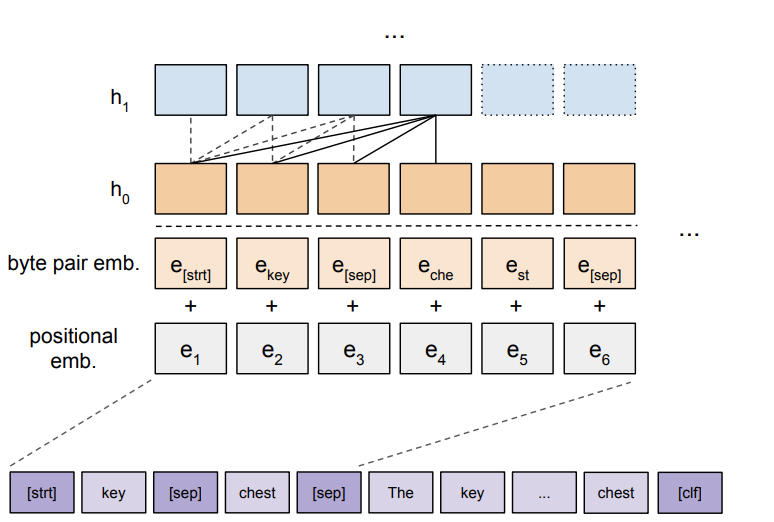
关系抽取输入为头尾实体有分隔符分割,后面跟着包含句子的token序列,以一个特殊的分类token作为结尾。由于模型处理输入是从左到右的,故论文在最开始添加关系论据,使得注意力机制在处理句子token序列过程中偏向于对应的token表征。
实验设置
文章在远程监督数据集NYT10上使用PCNN+ATT与RESIDE作为基准进行比较。
PCNN(The piecewise convolutional neural network): 将每个句子分割成实体对信息的左中右三个部分,后面接卷积神经网络编码与选择注意力机制得到一个bag-level的表示用于关系分类器。
RESIDE:使用双向循环门控单元(Bi-GRU)去编码句子,后面接一个图卷积神经网络编码显性提供的文法依赖树信息。然后将其与命名实体识别信息相结合,获得一个句子表示,句子表示通过选择注意力整合并输入到关系分类器中。
NYT10 Dataset
2010年Riedel等人提出,对齐Freebase与New York Times corpus,采用2005-2006年信息用于训练,2007年的信息用于测试,目前一般使用2016年Lin等人预处理后的版本数据集,该数据集开源。其测试集也是通过远程监督生成,所以仅仅能提供性能大概度量的方法,P@N是基于manual evaluation。
语言模型预训练
目标是反映微调在远程监督关系抽取任务的效率,所以直接重用2018年Radford等人发布的语言模型,扩展了模型的词库添加了task-specific tokens(开始,结束,分隔符)。
实验结果与结论
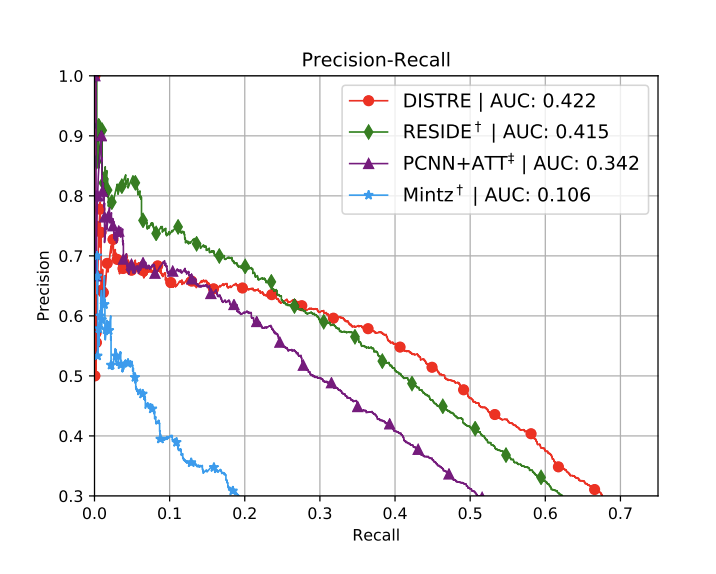
文章在结果上强调P-R曲线的balance问题,即整体表现良好(AUC面积最好),这在现实世界中可能具备很高的应用价值,baselines方法都体现出高召回率下drop early现象。
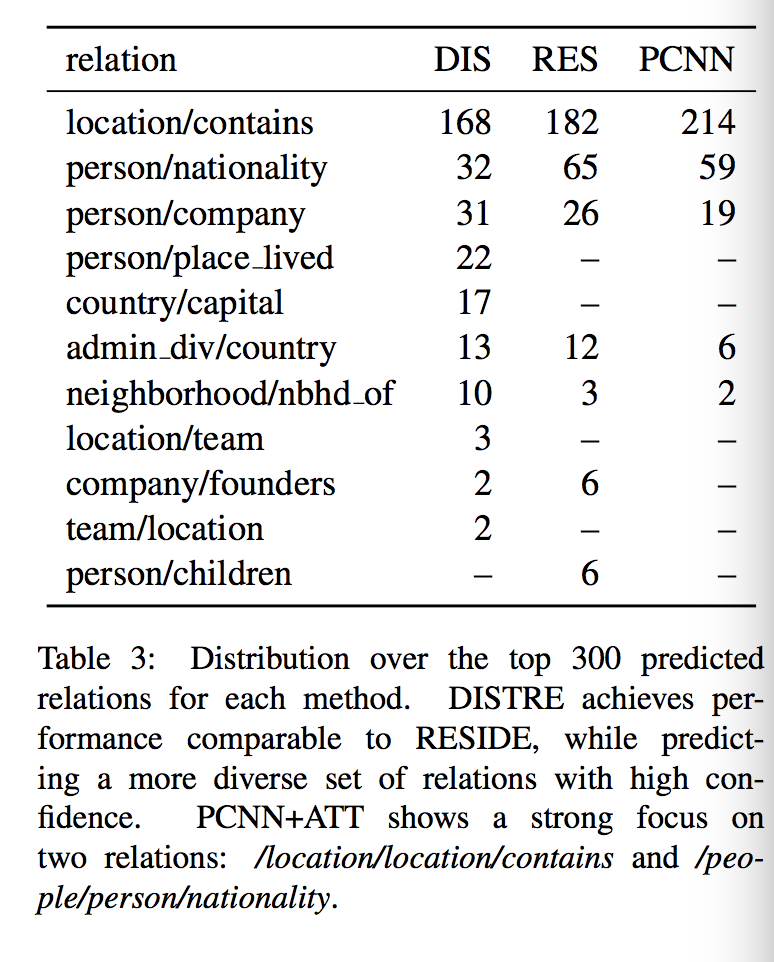
之所以使用手动评估原因在于hold-out dataset不能反映模型存在false positive标签于知识库信息不完整下的真实性能,故使用手工估计评估。文章模型DISTRE的手动评估结果显示大部分错误容易在高精确率错误标签中出现,例如/location/country/capital。高精确率的Top 300 相比于baselines种类更多。PCNN+ATT模型更关注提取实体类型信号和基本句法模式(包含关系与国籍关系占比91%),例如“LOC in LOC”,适合处理简单模式下的内容,后两种模型(RESIDE与DISTRE)可以处理更复杂的模式,比如实体距离更远。此外文章提出的模型也列出了一些句子级的预测结果。文章的TOP N(N=300)不是最高的,但是balance好。相比之下利用预训练模型获得隐性特征不同于RESIDE需要显性特征信息,增加domain与language的独立性,预处理可以省略。
文章扩展点在于通用结构引入额外的背景知识或者进行深度语言模型表示处理。
相关工作
关系抽取方向:最初RE任务基于统计分类器与核方法结合使用具体的句法特征实现,句法特征可以是词性、命名实体识别、形态特征(morphological features)、词网上下位(WordNet hypernyms)。后来被基于序列的方法所取代,具体的特征被替换为分布式(离散)的词与句法特征在神经网络中训练。最短文法依赖信息关注句子中的名词与动作,2015年Xu等人将其输入到基于LSTM的关系分类模型。2018年张等人在TACRED数据集上取得不错的效果,应用了a combination of pruning and graph convolutions to the dependency tree.
远程监督关系抽取方向:
- multi-instance learning and multi-instance multi-label learning (at least one)
- PCNN
- selective attention
- adversarial training
- noise model (Luo et al 2017)
- soft labeling
- graph convolutions and capsule networks(胶囊网络)
- previously methods
语言表示与Transfer Learning:
2018年Peters等人提出embeddings from language models(ELMo),在各种自然语言处理任务使用语境化词表征代替静态预训练词向量提高性能。通过无监督语言建模学习语言表示,显著提高文本分类性能,防止过度拟合,提高了样本效率。通用域的预训练与具体任务的微调有助于实现state-of-the-art的结果。2019年Radford等人发现增加语言模型的大小能更好的归纳下游任务,但是仍然欠拟合大规模文本集。

