摘要
考虑到Knowledge Base(KB)包含其他side information(边界信息),例如关系别名(founded/co-founded -> founderOfCompany)。RESIDE模型的提出为了充分利用来自知识库的边界信息提高关系抽取效果。模型使用实体类型与关系别名信息在预测关系过程施加软约束。RESIDE采用图卷积网络编码句法信息即使在有限的边界信息也可以取得不错的效果。代码开源
简介
大规模知识库:Freebase and Wikidata 应用于很多NLP任务中像问答、web搜索等。知识库本身是不全面的,关系抽取任务目标是抽取文本中实体对的语义关系填充知识库。关系对明确的条件下该任务可以被简单的建模为分类任务。
multi-instance learning目的在于松弛远程监督的假设,以前的假设两个实体在知识库中,之后所有提到所有句子均表达同样的关系。
在神经网络模型中,attention机制是用于缓解远程监督数据集的噪声。来自依赖文法的句法信息用于获取tokens之间的长期依赖。GCN方法编码文法依赖信息在2017年被提出。但是上述方法均依赖远程监督的有噪音示例。
Relevant side information例如实体类型信息有助于纠正关系预测,这是因为每个关系约束了对应的目标实体类型。同理关系别名也是有价值的。RESIDE充分使用知识库中实体类型与关系别名规则信息,在预测关系时增加软约束。
文章贡献:
一个全新的神经网络方法,利用知识库中的附加信息采用规则方法提高远程监督关系抽取效果。
RESIDE使用图卷积对句法信息进行建模,并被证明即使在有限的边信息情况下也具有竞争力。
- 通过实验证实了RESIDE效果好于baseline,且代码开源链接如下:http://github.com/malllabiisc/RESIDE
相关工作
远程监督: 句子会被错误标注,为了缓解这个问题,2010年Riedel等人采用multi-instance single-label learning 缓解远程监督问题,随后为了处理实体间关系重叠问题,学者们提出了multi-instance multi-label learning.
神经网络关系抽取:传统方法强烈依赖手工工程特征的质量。2014年Zeng提出一个端到端CNN方法获取相关词汇与句子级特征。后通过picewise max-pooling以及attention机制从多个有效句子中学习。另一方面,依赖树特征对关系抽取任务有着影响。2018年He等人使用依赖树输入到一个recursive tree-GRU模型中来提升结果。本文之所以选用图卷积神经网络在于GCN在句法信息建模上有着不错的效果。
关系抽取边界信息:实体描述信息被充分利用(Ji et al., 2017),但是这样的信息并非对所有实体均可利用。实体类型信息被利用主要是通过联合学习实体类型与关系抽取模型来降低远程监督带来的噪声。像Freebase这种知识库可以直接得到可靠的实体类型信息。本文中使用了实体类型信息与关系别名来源于KBs,同时还使用无监督的开放信息提取方法(Open IE),发现无需预定义本体的可能关系事实作为side information。
图卷积神经网络(GCN)
GCN on labeled Directed Graph
对于有向图而言,$G =(V,\varepsilon)$,$V$和$\varepsilon$分别表示顶点的集合与边的集合,一条边从点$u$到点$v$带有标签$l{uv}$被表示为$(u,v,l{uv})$,然而在有向边信息并非一定沿着其方向传播,这里定义了一个更新边的集合$\varepsilon^{‘}$包含转置边$(v,u,l_{uv}^{-1})$与自环$(u,u,T)$,其中$T$是一个特殊符号标记自环。定义每个节点$v$的一个初始向量表示$x_v$,使用GCN,计算得到一个更新的d维度隐层表示$h_v$,这里仅仅考虑它的近邻,公式如下:
其中$N(v)$反映$v$近邻的集合基于$\varepsilon^{‘}$,$f$为任意非线性激活函数。为了捕获多跳邻域,可以叠加多个GCN层。故第k层GCN可表示为:
Integrating Edge Importance
在自动构造的图中,有些边可能是错误的因此需要丢弃。GCN中的edgewise gating有助于抑制噪声边。实现方法即为图中的每条边分配一个相关分数。在第k层边$(u,v,l_{uv})$的重要性(edgewise gating)计算公式如下:
使用edgewise gating,最终的GCN对节点$v$的编码公式为:(文章中非线性函数使用Relu)
RESIDE
由三个组件组成:
- 句法句子编码:使用Bi-GRU编码连续的位置与词嵌入,为了捕获长范围依赖,输入依赖树到GCN将编码结果附加到每个token表示中。最终,attention在token级别应用抑制不相关的tokens,得到一个全句的编码结果。
- 边界信息采集:使用额外的监督来自KB、利用Open IE方法得到相关边界信息。
- 示例集整合:句法句子编码器的句子表示与前一步得到的关系embeding相连接。之后,使用句子级attention,这样整个包可以得到一个表示。在输入softmax分类器之前将表示与实体类型表示连接。
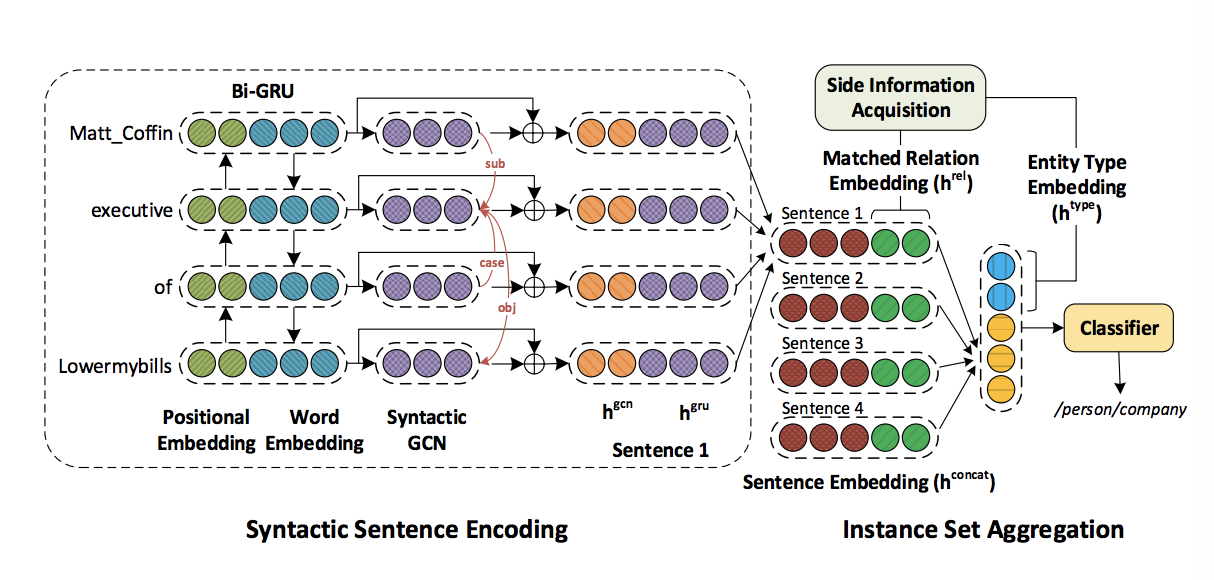
句法句子编码
采用k-dimensional Glove embedding表示每个token。使用的是相对于目标实体的相对位置。使用Bi-GRU的原因在于在许多任务中编码上下文token十分有效。Bi-GRU虽然可以捕获long context,但是通过依赖边才有助于获得long-range依赖。文法依赖树的生成采用Stanford CoreNLP。因为依赖关系图有55个不同的边标签,将所有标签合并在一起可以显著地将模型参数化。因此使用了三种边标签基于边的方向:[forward($\longrightarrow$),backward($\longleftarrow $),self-loop($T$)]。所以边标签定义如下:

将GCN中的语法图编码连接到Bi-GRU输出即$hi^{concat}=[h_i^{gru};h{i^{k+1}}^{gcn}]$,得到最终的token表示。由于tokens在RE任务中并非等同相关的,所以采用注意力机制计算每个token的相关度,公式如下:
$r$是一个随机查询向量。
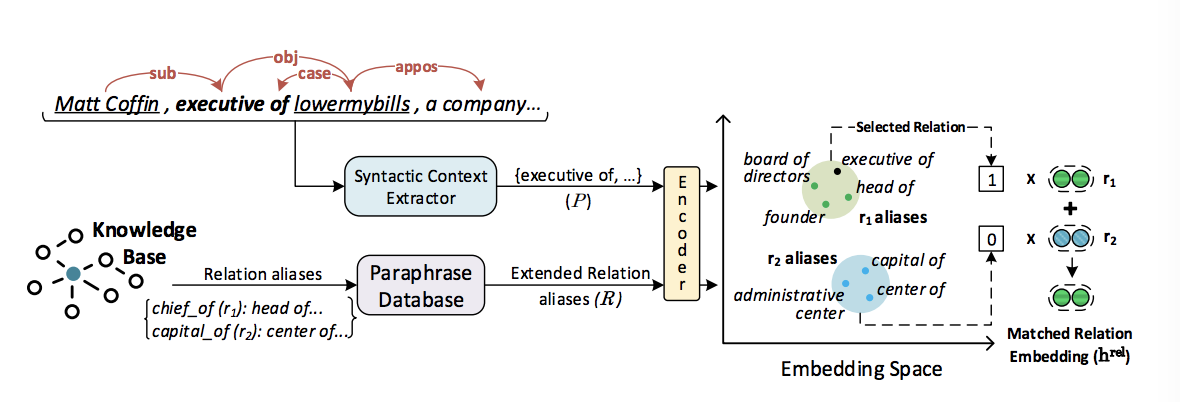
RESIDE使用Open IE提取实体间的关系短语,用$P$表示。P可以扩展通过文法依赖路径包含token的一跳距离。从P中提取的短语与关系别名$R$之间的匹配程度可以提供有关该关系与句子相关性的重要线索。相似度计算采用余弦相似度,找到与句子最为匹配的关系别名,使用余弦相似度阈值过滤掉噪声别名。模型RESIDE定义一个匹配关系编码$h^{rel}$与句子表示输入$s$相连。对于句子满足条件$|P| \gt 1$,这种情况下我们可能会得到多个匹配关系,在这种情况下,我们取它们嵌入的平均值
Note:仅提供关系名称作为别名也有助于取得较好效果。
对于实体类型边界信息,文章定义了一个$k_t$维编码叫做entity type embedding($h^{type}$)。当一个实体在不同语境下有多个类型时,文章取每个类型的编码均值。这个结果是用于连接目标实体与输入到关系分类器的最终包级别表示,来实现效果提升。为了避免参数过多,没有使用细粒度的112个实体类型,使用了38粗粒度类型。
Note:关系别名连接句子,实体类型(主语与宾语,即两个实体)连接包结构,最后输入到softmax分类器中求解。
实验设置与结果
数据集
- NYT10:Riedel 在2010年对齐Freebase relations与NYT corpus,标准数据集最为常用,53分类,在此不做介绍。
- GIDS:Jat等人创建Google Distant Supervision (GIDS)数据集通过扩展谷歌关系抽取数据集,即为每一个关系对添加额外的示例。该数据集保证至少一个假设在多示例学习中成立,这使得自动自动评估更可靠,无需人工验证,5个分类。
Baselines
传统方法:Mintz:多类逻辑回归模型; MultiR:多示例概率图模型; MIMLRE:联合多示例与多标签概率图模型;
神经网络方法:PCNN:基于卷积神经网络使用picewise最大池化处理句子表示;PCNN+ATT:就是在上个模型基础上加入句子级attention;BGWA:使用word-level与sentence-level的Bi-GRU关系抽取模型;
评估标准
与以前的工作相同,采用held-out evaluation,模型性能评估采用Precision-Recall curve和top-N precision度量。
结果分析
- 所有的非神经网络的baseline表现效果相对较差,因为它们使用的特征大多来自于NLP工具,特征可能是有错误的。
- 合并辅助信息(side information)有助于提高模型效果。(在组件移除效果也能体现)
- Attention 在远程监督关系抽取任务有着不错的效果。
- GCN有效编码句法信息(RESIDE组件移除后P-R 曲线下面积)
关于Relation Alias这一边界信息:文章实验采用四种不同的设置:
None:关系别名没有提供;
One:关系名作为别名;
One+PPDB:关系名使用Paraphrase Database(PPDB)扩展;
All:手动映射到相应的wikidata属性获取关系别名,补充关系别名少有的信息;
实验结果反映有限的关系别名也会提升性能,使用更多的别名信息有助于性能进一步提高。
结论
没有未来展望,就是GCN+side information在此不做总结了。

