摘要
问题:生成的训练数据通常包含大量噪音,可能导致在常规的监督学习中表现不佳。
文本提出一种先进的Cross-relation Cross-bag Selective Attention ($C^2SA$)使得远程监督关系抽取器能够实现噪声鲁棒训练。具体而言,文章采用句子级选择注意力机制减少噪声以及不匹配句子的影响,同时利用关系间的相关性来提高注意权重的质量。此外,代替将所有实体对看作是等价的,文章采用注意力机制关注更高质量的关系对。两种类型关系抽取器证实了本文提出方法的优越性,同时进一步的消融实验也证实了推理与技术的有效性。
简介
为了探索与分类在给定句子中一个实体对的关系,关系抽取(RE)在自然语言理解中扮演着一个至关重要的角色。一般的方法采用完全监督的模式、需要大量的人工标注,这些是高成本且费时的。为了缓解这样的依赖,学者们企图构建远程监督关系提取器,例如使用知识库(KB)自动生成训练数据。
尽管远程监督节省了成本与时间,但是远程监督方法是上下文无关的,因此对于句子级的RE其包含大量噪声。
噪声鲁棒训练模式:多示例学习方法有助于减少噪声增强模型鲁棒性。多示例学习把句子包视为基础的训练示例,每个包中的一组句子被标记为相同的知识库事实。通过包内选择,模型可以更加关注高质量的句子减少对噪音句子关注。Selective Attention企图为句子分配注意力权重之后结合包内所有句子用于训练。
然而,句子级可选择注意力(ATT)独立的生成每种关系类型的权重而忽略了关系类型间的关联。举例说明一句话反映低质量的die_in关系同时也可能表达了高质量的live_in关系。基于这个问题,文章提出Cross-relation Attention,在考察所有关系类型之间的关系后产生注意力权重。
本文放宽了一个训练实例只包含一个实体对的约束。具体来说,本文提出Cross-bag Attention结合不同的句子包,将这种组合结构称为superbag,并将其作为训练示例代替句子包,这使得我们更加关注高质量的句子包,减少知识库中过时或未表示的信息带来的噪声。
结合两种机制:Cross-relation与Cross-bag两个选择注意力机制是本文的核心部分。
相关工作
关系抽取任务,特别是有监督关系抽取任务已经有很多工作,但是大多基于额外的NLP系统获得词法特征。
深度神经网络能够自动学习潜在特征,循环神经网络在2012年被Socher等人使用,2014年起Zeng等人采用端到端卷积神经网络处理关系抽取任务。2016年起Zhou等人使用基于注意力机制的LSTM缓解CNN网络处理大跨度信息效果差的弱点。无论CNN还是RNN,甚至是强化学习都在关系抽取任务中有过应用。
远程监督的出现是为了节约大量标注的成本,而相同实体对的所有句子在同一个包内的多示例学习方法是为了抑制远程监督带来的噪音。选择性注意力机制的提出是为了筛选出包中高质量的句子特征。2017年Luo等人提出了一种基于过渡矩阵的噪音动态表征方法。2018年Feng等人使用强化学习在远程监督数据集上选择一个更可靠的子集并使用它训练分类器。为解决包级别噪音标注问题,Liu等人在2017年采用后验概率约束更正可能不正确的包标签。
本文提出的方法与选择注意力机制的不同主要有两方面:(1)是本文的方法考虑了多重关系之间的相互影响;(2)本文的方法评估了bag feature的质量,并减少袋级噪声标签问题的影响,而现有的选择性注意力当处理一个完全不正确的bag时是没有效果的。
方法
本文模型($C^{2}SA$)的提出通过考虑关系间的相关性提高句子级注意力的效果,并在另一个注意力层级筛选包级别特征。
如图一所示,关系抽取器包含两个组件:一个神经网络特征抽取器和一个输出层。对于神经网络特征抽取器,它可以抽取有用的特征进行关系分类,并可以使用任何的神经网络结构包括CNN与RNN。基于抽取特征,输出层对关系类型做出预测。模型训练过程整个分为四个步骤:首先为每个句子构建表示。之后,cross-relation选择性注意结合句子表征并生成句子包的表征。相似地,cross-bag选择注意力结合句子包表示生成超级包表示。最终loss基于superbag特征指导关系抽取器学习。
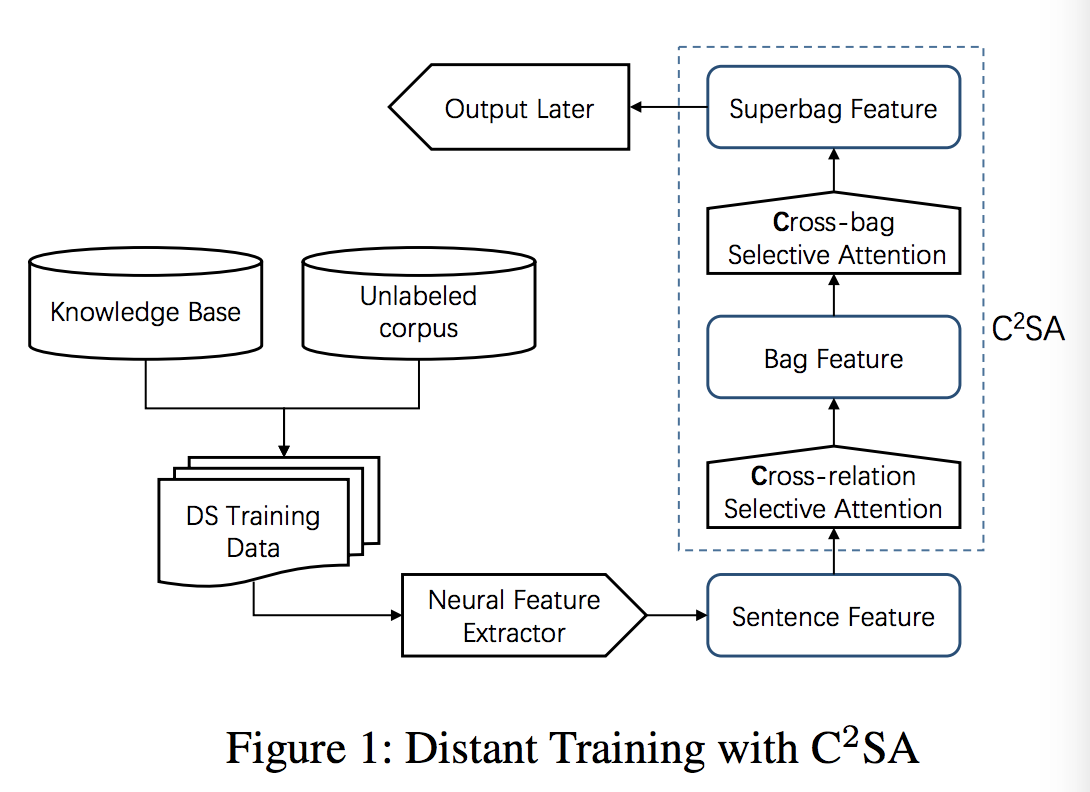
通常,神经网络特征抽取器可以被看作是一个神经网络句子编码器,它可以将句子编码成低维、固定长度的向量。本文在介绍方法默认采用CNN网络结构。
输入表示
encode in an entity-aware manner.预训练词向量,计算到两实体相对位置,位置有对应的位置编码表。位置编码表是随机初始化的并且在整个模型训练过程中进行更新。句子最大长度$m$有限,对于短句子,我们pad其他部分是0。
神经网络特征抽取器
文章采用piecewise-CNN,由卷积层和分段最大池化层。卷积层,输出结果$c$计算方法如下:
其中$Pi$是第i层的卷积核,$l$是核宽,$C{i,j}$是从词$w_i$到$w_j$的滑动窗口来自句子$C$,分段最大池化的使用是考虑了考虑了关系抽取任务具体的情境的,句子根据实体对分割成三部分,分别对每一部分采用最大池化处理,将三部分特征输出并连接,得到特征向量$x_i$,最后应用双曲正切函数处理输出的特征向量$x_i$。
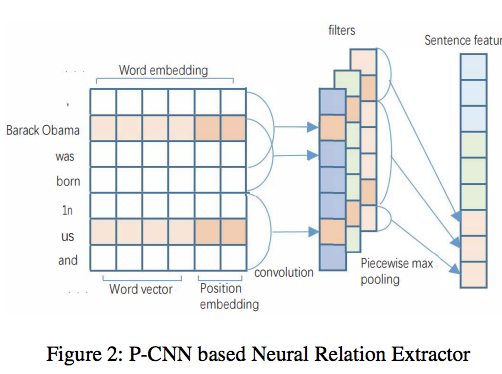
输出层
为计算每个关系的置信度,本文采用线性投影与softmax函数计算条件概率,另外本文采用droput策略防止过拟合。Dropout prevents co-adaptation of hidden units by randomly setting them to zero for a proportion $p$,故输出公式计算如下:
其中,h是随机Bernoulli变量向量使得概率$p$为1。
Cross-relation Selective Attention
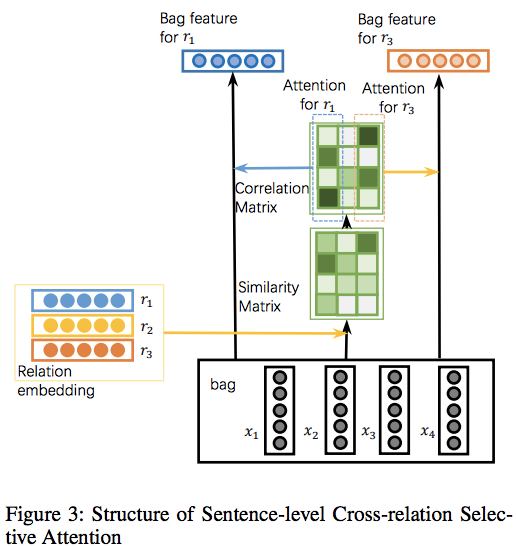
其目的旨在减少噪声或错误匹配句子的影响,计算选择注意力基于句子与关系间的相似性:
其中$r_k$是注意力参数对应于第k个关系。
为了捕获关系之间的相关性,我们使用bayes规则计算期望注意权重:
本文假设$P(j{th}sentence)$是均匀分布,采用softmax函数计算$P(k{th}relation|j_{th}sentence)$
简化概念,定义计算变量$P(k{th}relation|j{th}sentence)$简化为$\alpha{j,k}$,变量$P(j{th}sentence|k{th}relation)$简化为$\beta{j,k}$,因此属于第k个关系的包特征$B_i$可以计算为:
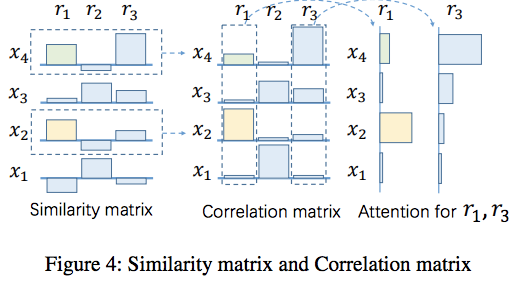
cross-relation selective attention不仅仅依赖于目标关系句子的相似性,也依赖于其他关系。例如在下图中$x_2$和$x_4$与$r_1$有相似的相似度,但是$x_4$更倾向于表示$r_3$关系。因此模型倾向于使用$x_2$特征生成bag特征并用此预测$r_1$关系。
Cross-bag Selective Attention
句子级注意力机制假设在包中至少一句话表达实体对的某种关系,远程监督在句子包级别存在噪音。可能大量关系对不能发现知识库中给定的表达。这种实体对会导致句子级关系抽取存在不匹配或噪声训练示例。
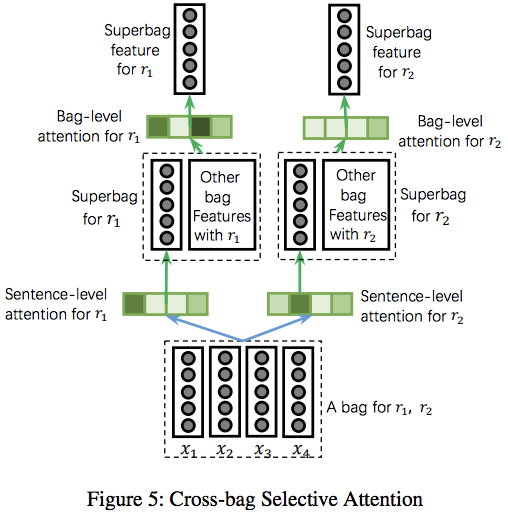
处理办法:本文结合几个包含相同关系类型的句子包,将注意力集中到更高质量的部分,定义superbag为$B=\lbrace B1,B_2,…,B{n_s}\rbrace$,其中$n_s$是超级包的大小,所有的$B_i$都由第k个关系类型表示。采用attention layer结合包,公式如下:
$S(rk,b{i,k})$即上文提到的余弦相似度计算,$rk$表示注意力参数对应于第j个关系,$b{i,k}$是包的表示对应于$B_i$的第k种关系。
最终模型目标函数训练采用负对数似然实现。
实验
因为$C^2SA$与模型有关,只用于学习阶段,因此本文使用两种类型的神经关系提取器进行实验。使用人工标注的测试库在句子级关系抽取任务上进行实验取得了state-of-the-art结果。进一步采用case study与ablation实验,验证cross-sentence 与cross-bag选择注意力机制的有效性。
数据集
训练集于之前一致使用NYT10作为训练集,53个分类,数据集包含522611个句子,281270实体对与18252知识库事实。
一个实体对表达关系的概率就是最大化这个关系所有包含实体对的句子提及的概率。
baselines
- PCNN+ATT:使用普通的句子级选择注意力结合每个包的句子特征,基于每个包的表示在PCNN模型下训练。
- BLSTM+2ATT:也是使用普通的句子级选择注意力机制,不同于PCNN采用的是BLSTM模型附加一个额外的word-level attention单元。
- PCNN+ATT+RL:整合强化学习改善PCNN+ATT,它采用学习策略选择训练集子集PCNN+ATT模型。
- PCNN+ATT+softlabel:增强PCNN+ATT模型的效果通过使用后验概率约束修正潜在错误包标签。
corpus-level Task
本文P-R曲线评估方法采用语料库级关系抽取。
测试集是2007年freebase标注构建的,包含172448句子,96678实体对与1950 知识库事实。
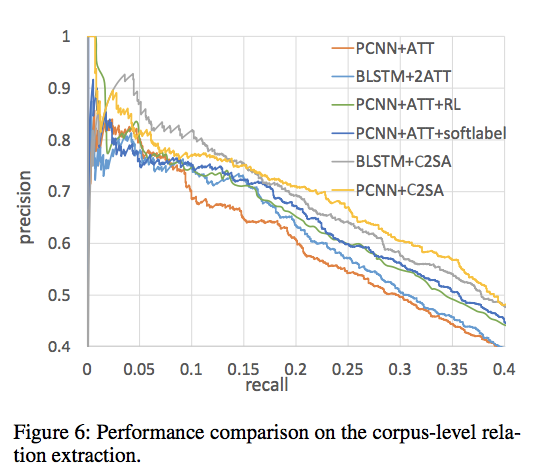
性能比较方面从P-R曲线来看,基于PCNN的方法与基于BLSTM的方法没有明确的区别,尽管baseline方法PCNN效果比BLSTM差但是本文提出的$PCNN+C^2SA$与$BLSTM+C^2SA$相比PCNN更好。
sentence-level Task
与语料库级任务不同,该任务旨在识别特定句子中实体对的关系类型。本质上是将句子表示输入到输出层中并观察预测结果。
在该任务中采用Hoffmann2011年发表文章的数据集,包含395个人工标注结果,相比于corpus-level任务该数据集比较小,但是考虑到人工标注的价值,这项分析是有意义的。
在模型比较方面除了Base的PCNN+ATT与BLSTM+2ATT外还考虑了$C^2SA$的两种变体:$CRSA$和$C^2SA-dot$。其中$CRSA$仅使用cross-relation选择注意机制;$C^2SA-dot$将公式中余弦相似度部分均改为点乘(dot product)。
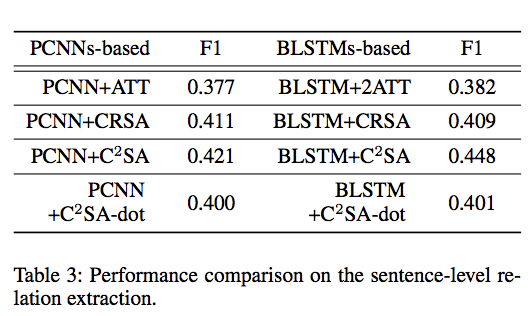
实验结果反映了两个重要信息:(1)本文提出的cross-relation与cross-bag对模型效果的提升都有效;(2)余弦相似度代替点乘作为评分函数的一部分是非常有效的。
模块切除研究(Ablation Study)
为证明cross-relation机制的有效性,比较$CRSA$与$ATT$,因为二者均在句子包级别上进行训练。而cross-bag是基于句子包表示的,因此通过比较$CRSA$与$C^2SA$来证明cross-bag的有效性。为保证公平的比较,本文分别对PCNN与BLSTM based方法都进行了Precision-Recall curve评估。
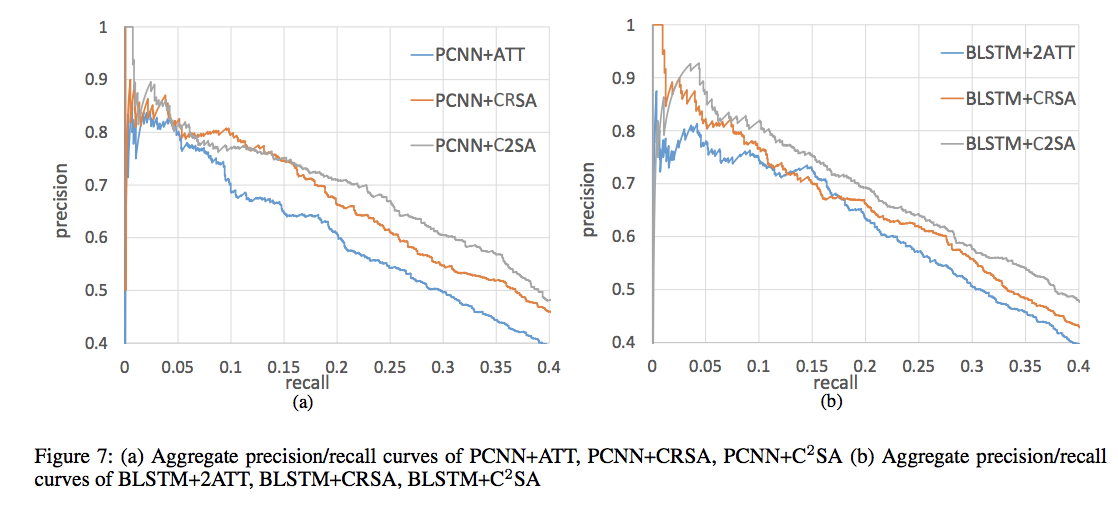
文章说明了PCNNs-based的方法比BLSTMs-based方法效果好很可能是由于不同神经网络特征提取器的特征差异造成的。CNNs模型能够很好地提取句子中反映在特征向量维度上的局部信息(如触发词),这一点导致基于余弦相似度的注意机制具有更好的性能。
另一方面,$C^2SA$与$CRSA$之间的表现差距证实了一些句子包相比其他的有更高的质量。主要说明了模型在superbag level上训练会有更好的鲁棒性,case study实验也是支持这一观点。
Case Study
Noise of Distant Supervision at Bag-level
本文随机采样20种不同的NYT数据集中关系类型,随机选择100个实体对构建100个句子包。手工检验它们的质量,这些句子包包含483个句子,句子包的质量效果一般(一般句子级是用于考虑句子内的关系),如下图。
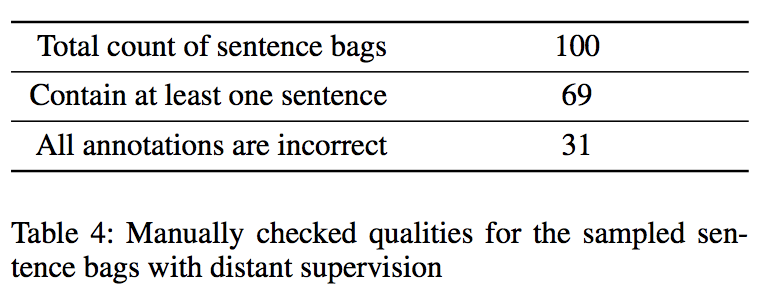
从结果上来看,大约31%的句子包甚至没有包含一个正确标注的句子。因此,得出结论如下:应对远程监督的噪声,采用superbag-level进行训练是有价值的。
Effectiveness of Cross-bag Selective Attention
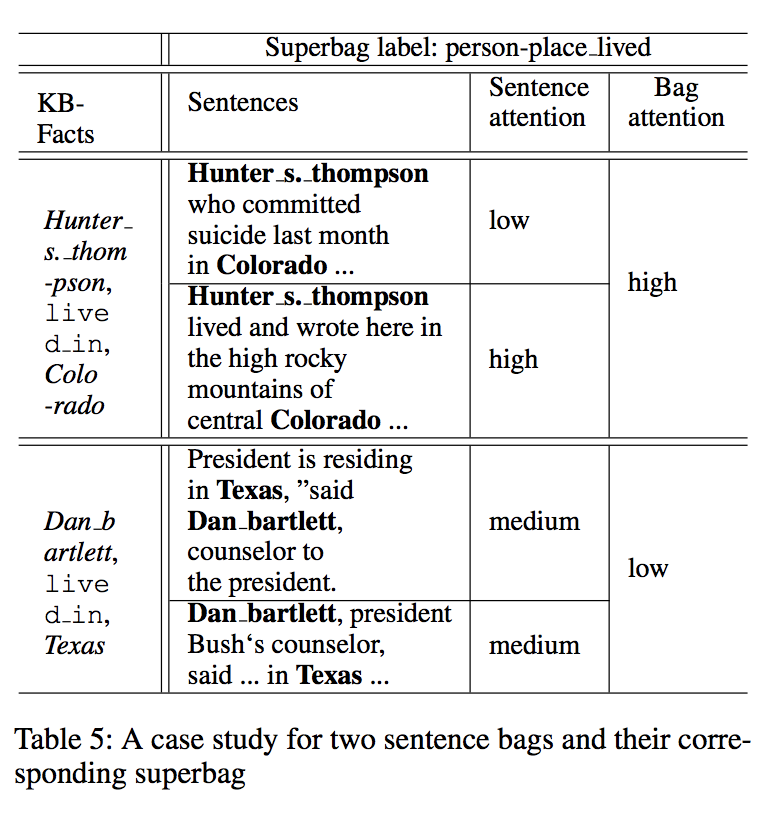
下图显示一个表示关系类型lived_in的superbag,它两个句子包。经过观察发现仅有一个句子正确的标注在第一个句子包中,二第二个句子包所有句子均不匹配知识库反应的关系事实。cross-bag选择注意力允许模型关注更多句子包从而获得更高的质量。
结论与展望
本文提出cross-relation cross-bag 选择注意力,建立一个实体关系模型有效地学习真实表达关系的特征从包含噪声的远程监督数据中。实验证明所提出的模型能更好的学习高质量的bag feature对比于现存文献。跨包注意力选择机制有助于进一步提升性能通过使用高质量的bag features。

