摘要
本文提出了一种神经网络关系抽取方法,用于处理远程监督产生的噪音训练数据。先前的研究主要通过设计具有包内注意力的神经网络,专注于句子级的降噪。本文同时考虑了包内注意力与包间注意力机制,以便分别处理语句级别和包级别的噪音。首先,通过使用包内注意力对句子嵌入进行加权来计算相关示例包的表示。在此,将每个可能的关系用作关注度计算的查询,而不是仅使用常规方法中的目标关系。此外,通过使用基于相似度的包间注意力模块对示例包表示加权来计算训练集中共享相同关系标签的一组示例包的表示。最后,在构建关系提取器时,将一个示例包组用作训练样本。New York Times数据集上的实验结果证明了提出的包间和包内注意力模块的有效性。与该数据集上最新方法相比,其方法具有更好的关系 抽取精度。
其开源代码网址为https://github.com/ZhixiuYe/Intra-Bag-and-Inter-Bag-Attentions,经本人验证略作改动可在CPU环境下复现使用,运行时长约20小时左右。
简介
关系抽取是自然语言处理(NLP)中的一项基本任务,其目的是提取实体之间的语义关系。例如,句子“[Barack Obama] was born in [Hawaii]表示实体对Barack Obama和Hawaii之间的bornin关系。
常规的关系抽取方法,例如(Zelenko et al., 2002; Culotta and Sorensen, 2004; Mooney and Bunescu, 2006),都采用监督训练,并且缺乏大规模的手工标记数据。为了解决这个问题,提出了一种远程监督方法(MIntz等,2009),该方法可以自动生成训练关系抽取模型的数据。远程监督假设,如果两个实体参与关系,则提及这两个实体的所有句子都表示该关系。不可避免地,在远程监督标记的数据中会存在噪音。例如,对齐New York Times与Freebase的关系精度只有大约70%。
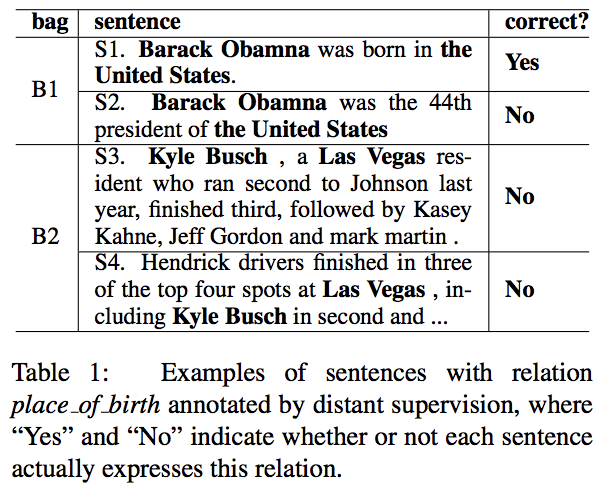
因此,Riedel等人提出的额关系抽取方法认为,远程监督假设额过于强大,因此将其放宽为at-least-once假设。此假设表明,如果两个实体参与关系,则至少一个提及这两个实体的句子可能表示该关系。表1中句子S1和S2显示了一个示例。此关系抽取方法首先将远程监督提供的训练数据划分为多个包,其中每个包是一组包含相同实体对的句子,然后,通过对每个包中的句子进行加权得出包表示。期望减少带有不正确标签语句的权重,并且主要使用带有正确标签的语句来计算包表示。最后,将示例包用作训练关系抽取模型的样本,而非单个语句。
近年来,已经提出了许多使用具有注意力机制的神经网络关系抽取方法,以减轻at-least-once假设下的噪音训练数据的影响。然而,这些方法仍然存在两个缺陷。首先,在训练阶段,仅使用每个示例包的目标关系来计算注意力权重,以从句子嵌入中得出多示例包表示。在这里,本论文认为,应当以一种关系感知的方式来计算包的表示形式。例如,表1中的示例包B1中包含两个句子S1和S2。当此包被分类为BornIn关系时,句子S1的权重应高于S2,但当分类关系为关系PresidentOf时,S2的权重应更高。其次,at-least-once假设忽略了嘈杂的包问题,这意味着一个包内所有语句都被错误地标记,表1中的袋子B2显示了这样的一个示例。
为解决现有方法的两个不足,本文提出了一种多层次注意力的神经网络用于远程监督关系抽取。在实例/句子级别,即包内层次,所有可能的关系都被用作查询来计算关系感知的包表示,而不是使用每个包的目标关系。为了解决嘈杂的示例包问题,采用多示例包组作为训练样本,而不是单个包。在这里,一个多示例包组由训练集中共享相同关系标签的包组成。使用基于相似度的包间注意力模块通过对包表示的加权来计算多示例包组的表示。
本文的贡献包含三部分。首先,提出了一种改进的包内注意力机制,以导出用于关系抽取的关系感知的包表示。其次,引入包间注意力模块来处理嘈杂的包问题,该问题被at-least-once假设所忽略。第三,本文提出的方法比相同数据集上的最新模型具有更高的抽取精度。
相关工作
先前的一些工作将关系提取视为一种有监督的学习任务,并设计了手工制作的特征来训练基于内核的模型。由于缺乏大规模的人工标注数据用于监督训练,提出了远程监督方法,该方法将原始文本自动对齐到知识库中,生成实体对的关系标签。然而,这种方法受到了标签噪音问题的困扰。因此,随后的一些研究将远程监督关系抽取看作是一个多示例学习问题,从一个句子集中提取关系,而不是从单个句子中提取关系。
随着深度学习技术的额发展,已经开发了许多基于神经网络的远程监督关系抽取模型。Zeng等人提出了分段卷积神经网络来建模句子表示,并选择最可靠的语句作为包表示。Lin等人采用PCNN作为句子编码,提出了一种包内注意力机制,通过包内所有语句表示的加权和计算包表示。Ji等人采用相似的注意力策略,并结合实体描述来计算权重。Liu等人提出一种软标签方法来减少嘈杂实例的影响。所有这些方法都用一个加权的语句嵌入总和表示一个示例包,并在训练阶段使用相同的包表示计算包被分类到每个关系中的概率。在本论文提出的方法中,包内注意是以一种关系感知的方式计算的,这意味着不同的包表示被用来计算不同关系类型的概率。此外,这些现有的方法主要集中在包内注意,忽略了嘈杂的多示例包问题。
还有一些鲁棒的远程监督关系抽取数据过滤策略被提出。Feng等人与Qin等人均采用强化学习训练实例选择器,并过滤出标签错误的样本。他们分别根据关系分类器的预测概率和性能变化来计算模型的奖惩。Qin等人设计了一个对抗性学习过程,通过基于策略梯度的强化学习来构建句子级生成器。这些方法都是在句子级过滤掉有噪声的数据,也不能很好地处理有噪声的多示例包问题。
方法
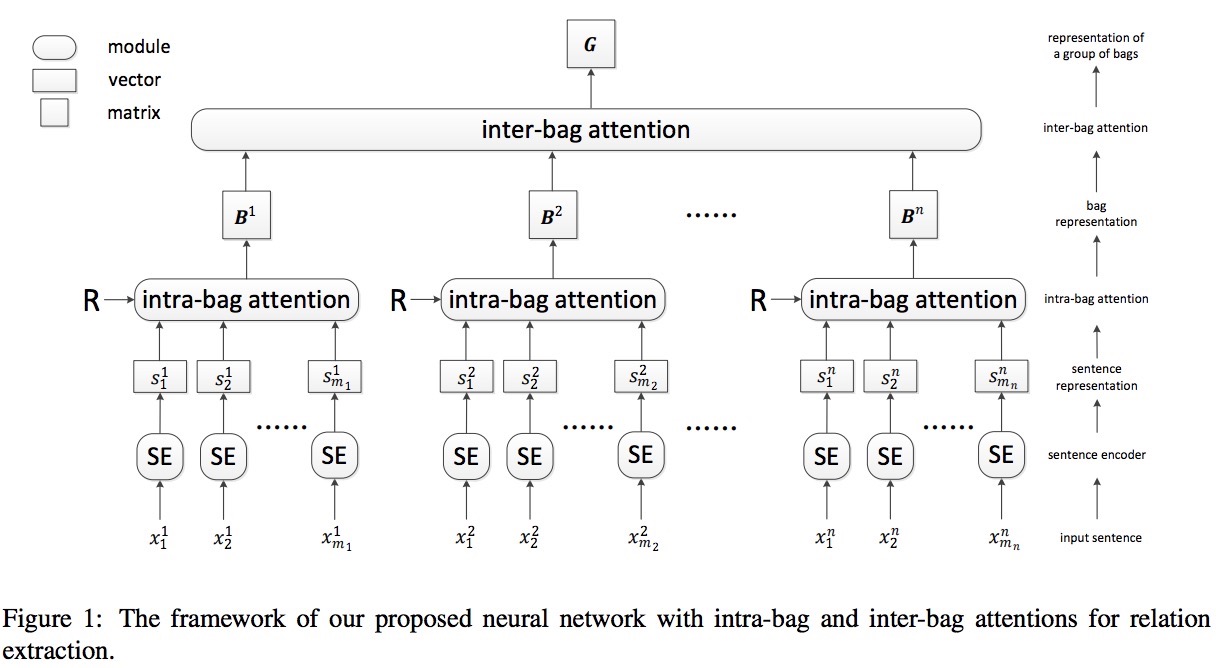
在本小节中,本论文介绍了一个带有包内和包间注意力机制的神经网络用于远程监督关系抽取。让$g=\lbrace b^1,b^2,…,b^n\rbrace$代表一组具有远程监督给出的额相同关系标签的包,以及$n$组内包的个数。让$b^i=\lbrace x^i1,x^i_2,…,x^i{mi}\rbrace$代表示例包$b^i$内所有句子,并且$m_i$表示$b^i$包内句子数。让$x^i_j=\lbrace w^i{j1},w^i{j2},…w^i{jl{ij}}\rbrace$表示在第$i$个包内第$j$个句子,并且$l{ij}$是它的长度(即,词的数量)。模型框架如图1中所示,共有三个主要模块。
- 句子编码器:给定一个句子$x^i_j$和在这个句子中两个实体的位置,采用CNN或PCNN推导句子表征$s^i_j$。
- 包内注意力机制:给定在$b^i$包内所有句子的句子表示和一个关系嵌入矩阵$R$,注意力权重向量$\alpha^i_k$与包表示$b^i_k$由所有关系计算得到,其中$k$是关系索引。
- 包间注意力机制:在给定g组的所有包的表示的情况下,通过基于相似度的注意机制进一步计算权重矩阵$\beta$,得到包组的表示。
句子编码器
单词表示
在句子$x^ij$中每个单词$w^i{jk}$首先映射到一个$dw$维度的单词嵌入。为了描述两个实体的位置信息,本文还采用了Zeng等人提出的位置特征(PFs)。对于每个单词,PFs描述当前词和两个实体之间的相对距离,并进一步映射到两个$d_p$维度向量$p^i{jk}$和$q^i{jk}$。最终,这些三个向量被连接得到$d_w+2d_p$维度的词向量$w{jk}^i=[e{jk}^i;p{jk}^i;q_{jk}^i]$。
分段卷积
对于句子$x^ij$,单词表示矩阵$W^i_j \in R^{l{ij}\times(d_w+2d_p)}$首先使用$d_c$维度的过滤器输入到CNN中。之后,使用分段最大池化从CNN输出的三个部分中提取特征,并且分段边界由两个实体的位置信息决定。最终句子表示$s^i_j \in R^{3d_c}$可获得。
包内注意力机制
让$S^i \in R^{m_i\times 3d_c}$表示$b^i$包内所有的句子表示,并且$R \in R^{h \times 3d_c}$代表一个关系嵌入矩阵,其中$h$是关系的数量。
与传统方法不同的是,本论文的方法为关系分类导出了统一的包表示,本论文的方法计算包表示$b^i_k$为包$b^i$在所有可能关系的条件下为:
其中$k\in \lbrace 1,2,…,h \rbrace$是关系索引并且$a^i{kj}$是$b^i$包内第$k$个关系与第$j$个句子之间的注意力权重。$\alpha^i{kj}$能够进一步定义为:
其中$e^i_{kj}$是包$b^i$中第$k$个关系查询和第$j$个句子之间的匹配度。在本论文的实现中,采用向量之间的简单点积来计算匹配度为:
其中$r_k$是关系嵌入矩阵$R^2$的第k行。
最终,包$b^i$的表示组成图1中的矩阵$B^i \in R^{h\times 3d_c}$,其中每一行对应这个多示例包的一个可能的关系类型。
包间注意力机制
为了解决含噪示例包问题,设计了一个基于相似度的包内注意力模块,动态降低带有噪音包的权重。直观上,如果两个包$b^{i1}$和$b^{i2}$都标记为关系k,他们的表示$b^{i_1}_k$与$b^{i_2}_k$应当相互接近。给定一组具有相同关系标签的包,论文将更高的权重分配给与该组中其他示例包相近的包,因此,包组$g$的表示形式可以公式化为:
其中$gk$是图1中矩阵$G \in R^{h \times3d_c}$的第k行,$k$是关系索引,并且$\beta{ik}$组成了注意力权重矩阵$\beta \in R^{n\times h}$,每一个$B_{ik}$被定义为:
其中,$\gamma_{ik}$描述了标注示例包$b^i$带有第$k$个关系的置信度。
受自注意力算法的启发,该算法使用向量本身计算一组向量的注意权重,本论文根据它们自身的表示来计算行李的权重。数学上,$\gamma_{ik}$被定义为
在他们的实现中,函数相似性是一个简单的点积。
而且,为了防止向量长度的影响,所有包表示$b^i_k$标准化为单位长度$\overline{b^i_k}=b^i_k/||b^i_k||_2$在计算包间注意力前。
之后,将包组$g$分类为关系$k$的得分$o{k}$通过$g{k}$和关系嵌入$r_{k}$计算为
其中$d_k$是一个偏倚项。最后,使用softmax函数来获得包组$g$被归类为第$k$个关系:
需要注意的是,公式的计算使用了相同的关系嵌入矩阵$R$。类似于Lin等人,dropout策略被应用于包表示$B^{i}$以防止过拟合。
实现详情
数据打包
首先,训练集中包含相同两个实体的所有句子都被累积到一个包中。然后,将共享相同关系标签的每$n$个包捆绑在一起。应当注意的是,在该论文的方法中,包组是一个训练样本。因此,也可以通过将多个包打包成一个批量,以小批量的方式训练模型。
目标函数与优化
在论文的实现中,目标函数被定义为:
其中,$T$是所有训练样本的集合,$\theta$是模型参数的集合,包括词嵌入矩阵,位置特征嵌入矩阵,CNN权重矩阵和关系嵌入矩阵。通过小批量随机梯度下降(SGD)最小化目标函数$J(\theta)$来估算模型参数。
训练与测试
如上所述,在本文提出的方法的训练阶段,将具有相同关系标签的n个包累积到一个包组中,并计算包表示的加权总和已获得包组的表示$G$。由于每个包的标签在测试阶段都是未知的,因此在处理测试集时将每个单个包视为一个包组(即,$n=1$)
而且,类似于Qin等人的方法,该论文仅将包间注意应用于阳性样本,即关系标签不是NA的包。原因是么没有关系的示例包的表示总是多种多样的,很难为它们计算合适的权重。
预训练策略
在方法的实施中,采用了与训练策略。该论文首先只训练包内注意力模型,直到收敛为止。然后,添加包间注意模块,并进一步更新模型参数,直到再次收敛。初步的实验结果表明,与从一开始就考虑包间注意相比,这种策略可以带来更好的模型性能。
实验
数据集与评估指标
实验采用了NYT数据集。该数据集由Riedel等人首次发布,并已广泛用于之前的远程监督关系抽取研究中。这个数据集是通过将Freebase与NYT的语料库自动对其生成的,共有52个实际关系和一个特殊关系NA,表明两个实体之间没有关系。
在先前的研究之后,本论文在held out数据集测试集上评估模型。在他们的实验中,采用了精确率-召回率曲线,曲线下的面积值(AUC)与Precision@N值作为评估指标。他们的实验给出的所有数值结果都是10次重复训练的平均值,并且从重复中随机选择P-R曲线,因为它们之间没有明显的视觉差异。
训练细节与超参数
表2列出了实验中使用的所有超参数。其中,大多数遵循Lin等人的参数设置。初始化也采用了由Lin等人发布的50维单词嵌入。这些词汇包含了New York Times语料库中出现过100多次的词汇。
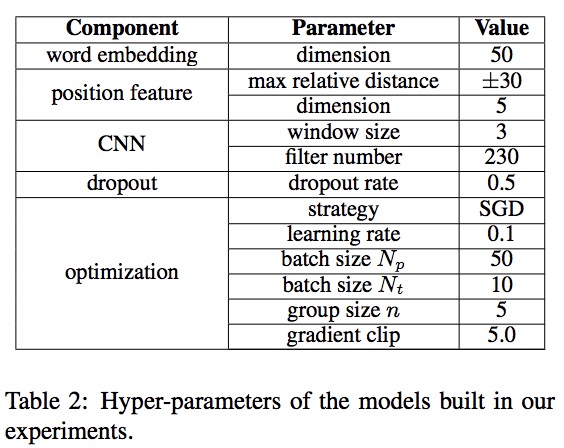
两种不同批次大小$Np$和$N_t$分别用于预训练和训练。在该论文的实验中,使用训练集进行网格搜索,以确定$n$,$N{p}$和$Nt$在范围$n \in \lbrace 3,4,…,10\rbrace$,$N_p \in \lbrace 10,20,50,100,200 \rbrace$和$N{t} \in \lbrace 5,10,20,50 \rbrace$。请注意,增加包组大小$n$可能会增强包间注意的效果,但会减少训练样本的数量。当$n=1$时,将失去包内注意的影响。为了进行优化,该论文采用了初始学习率为0.1的小批量SGD。学习速度每100000步下降到十分之一。在实验中,仅具有包内注意的预训练模型收敛在300000步以内。因此,用于训练袋间注意的模型的初始学习率设置为0.001。
整体表现
实现了8个模型进行比较。表3列出了这些模型的名称,其中CNN和PCNN分别表示在句子编码器中使用CNN或分段CNN,ATT-BL表示Lin等人提出的基线包内注意方法,ATT-RA表示本论文提出的基于关系的包内注意方法,BAG-ATT表示本论文提出的包间注意方法。在ATT-BL方法的训练阶段,用于注意权重计算的关系查询向量被固定为与每个包的远程监督标签关联的嵌入向量。在测试阶段,应用所有关系查询向量分别计算关系的后验概率,并选择概率最高的关系作为分类结果。这些模型的整个P-R曲线给出的AUC值的平均值和标准差如表3中所示,以进行定量比较。随后,本论文还在图2和图3中绘制了这些模型的P-R曲线,其召回率小于0.5以进行可视化比较。
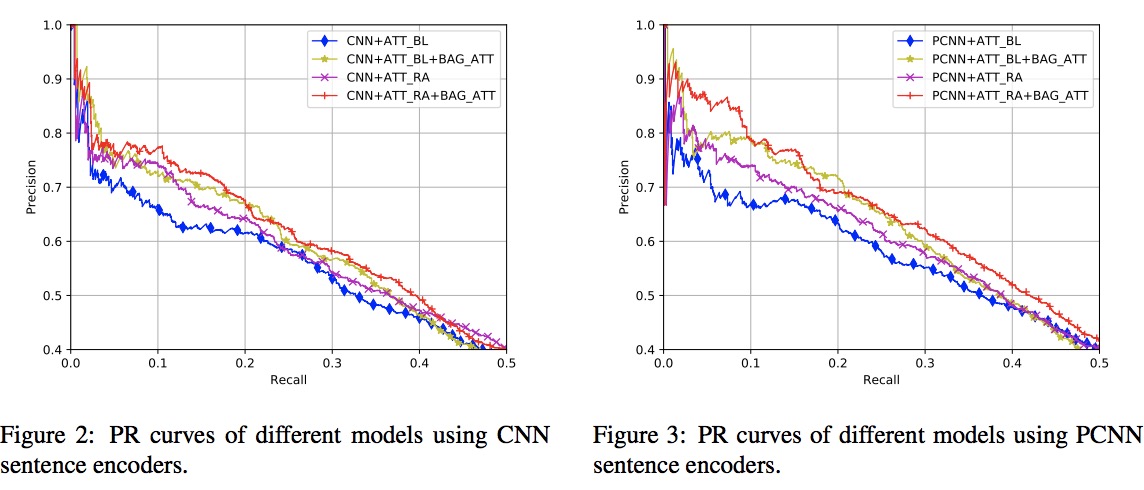
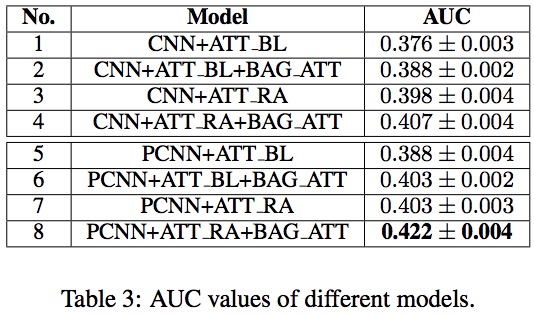
从表3,图2和图3,本论文有以下观察结论:(1)与先前的Zeng等人研究成果相似,PCNN作为句子编码器比CNN更好。(2)使用CNN或PCNN句子编码器时,ATT-RA的性能均优于ATT-BL。这可以归因于ATT-BL方法在训练时推导包表示时只考虑了目标关系,而ATT-RA方法则使用所有关系嵌入作为查询来计算包内注意权重,从而提高了包表示的灵活性。(3)对于句子编码和两种包内注意方法,使用BAG-ATT的模型总是比不使用BAG-ATT的模型有更好的性能,这一结果验证了本论文提出的包间注意方法在远程监督关系提取中的有效性。(4)将PCNN句子编码器于本文提出的包内和包间注意相结合,可以获得最佳的AUC性能。
与以往工作的比较
P-R曲线
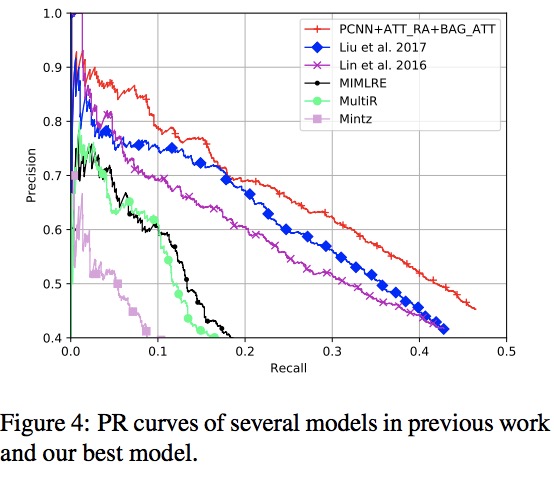
图4比较了先前工作中的几种模型和本论文的最佳模型PCNN+ATT-RA+BAG-ATT的P-R曲线,其中MIntz、MultiR和MIMLRE是常规基于特征的方法,以及Lin等人和Liu等人是基于PCNN的方法。为了与Lin等人和Liu等人进行公平比较,该论文还绘制了仅具有前2000个点的曲线。可以看到,本论文的模型取得了比所有其他模型都具有更好的P-R性能。
AUC值
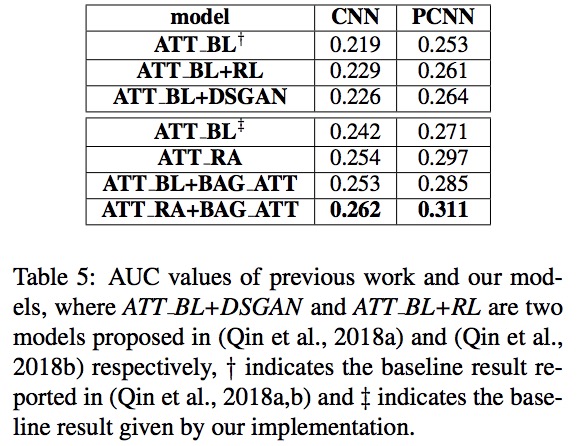
ATT-BL+DSGAN(QIn等人)和ATT-BL+RL(QIn等人)是近年来两个基于强化学习的数据过滤远程监督关系抽取的研究,报告了由前2000个点组成的P-R曲线的AUC值。表5比较了这两篇论文中报告的AUC值和本论文提出的模型的结果。可以看到,将所提出的ATT-RA和BAG-ATT方法引入到基线模型中比使用所提出的方法取得了更大的改进。
包内注意力的影响
继Lin等人之后,该论文同样使用一个以上的训练句子来评估实体对模型。随机抽取每个测试实体对的1,2和所有句子,构建3个新的测试集。表2列出了这三个测试集上该论文提出的模型给出P@100、P@200、P@300值及其平均值,以及Lin等人和Liu等人的最佳结果。这里P@N是指关系分类结果的精度,在测试集中,前N个最高概率值。
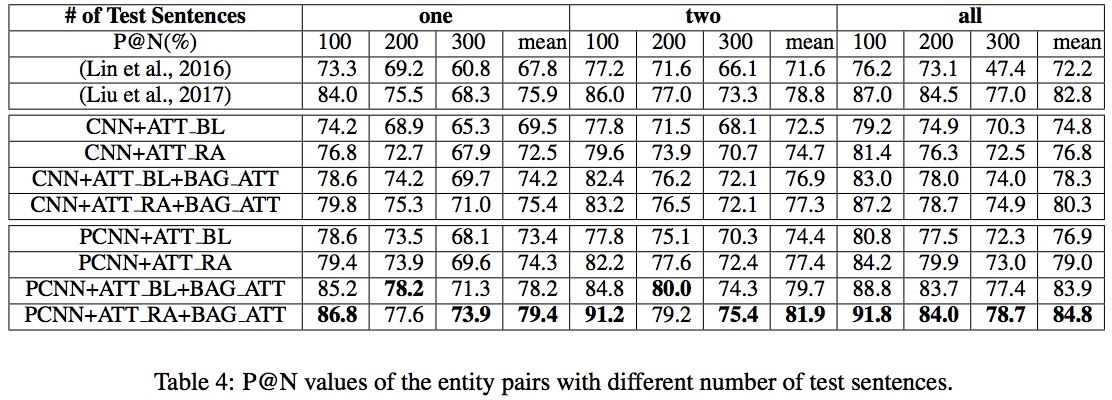
可以看到该论文提出的方法比以前的工作获得了更高的P@N值。此外,无论采用PCNN还是BAG-ATT或是ATT-RA方法在每个实体对只有一个句子的测试集上的表现均优于ATT-BL方法。注意,当包中只有一个句子时,ATT-BL和ATT-RA的解码过程是等价的。因此,从ATT-BL到ATT-RA的改进可以归因于ATT-RA在训练阶段以关系感知的方式计算了包内注意力权重。
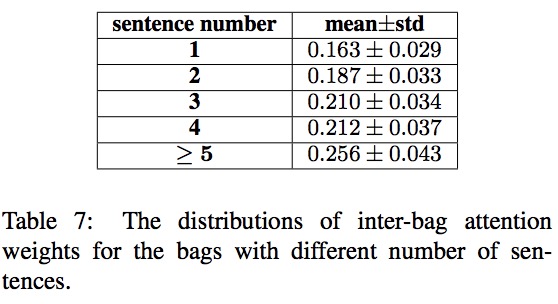
包间注意的权重分布
本论文根据每个包内的句子数将训练集分成5部分。对于每个包,记录由PCNN+ATT-RA+BAG-ATT模型给出的包间注意力权重。然后,计算训练集各部分的注意权重平均值和标准差,如表7所示。从这个表中我们可以看出,训练句子数较少的包通常被分配较低的包间注意权重。这一结果与Qin等人的发现一致,即训练句子较少的实体对更具有可能具有不正确的关系标签。
案例分析
关系“/location/location/contains”的一个测试集示例如表6所示。包组中包括3个多示例包,分别由2句子、1句子和2句子组成。本论文使用PCNN+ATT-RA+BAG-ATT模型计算了该包组的包内和包间注意,目标关系的权重也显示在表6中。
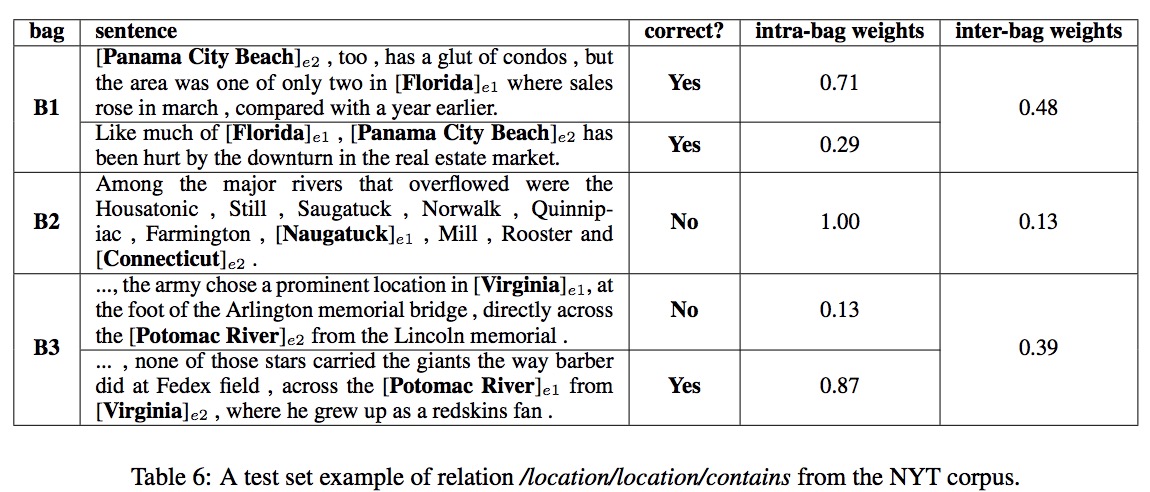
在本例中,第二个包是一个嘈杂的包,因为该包中的唯一一句话没有表示两个实体Naugatuck和Connecticut之间的“/location/location/contains”关系。在传统的训练方法中,这三个包被同等对待。引入包间注意机制后,如表6最后一列所示,该噪声包的权重显著降低。
结论
在本文中,提出了一种具有包间和包内注意力的神经网络,以解决远程监管关系提取中的嘈杂句子和嘈杂包问题。 首先,通过句子嵌入的加权总和来计算关系感知包表示,其中嘈杂的句子预期具有较小的权重。 此外,包间注意模块被设计为通过在模型训练期间动态计算示例包级注意权重来处理嘈杂的袋问题。 New York Times数据集上的实验结果表明,与仅使用常规包内注意力的模型相比,他们的模型取得了显著且一致的改进。 处理关系抽取的多标签问题并将外部知识集成到模型中将是他们未来工作的任务。

